Why probably not what you're looking for? I say this not to make the library seem more alluring, but because HTMLString is designed to help with a niche set of problems related to developing an HTML content editor.
Unlike most HTML parsers which generate tree structures, HTMLString generates a string of characters each with its own set of tags. This flat structure makes it easy to manipulate ranges (for example - text selected by a user) as each character is independent and doesn't rely on a hierarchical tag structure. This does however have its limitations (hence my opening statement).
The structure of an HTMLString string is illustrated in the diagram below:
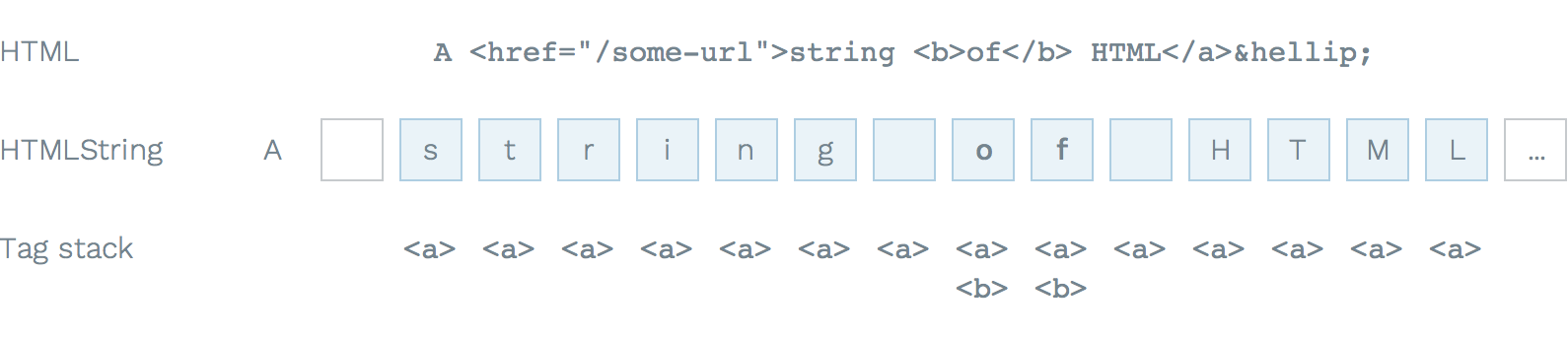
Limitations
As I mentioned already, there are some limitations to this approach when dealing with HTML;
- The parser is designed to handle content containing in-line elements, as a rule of thumb anything that's valid inside of a paragraph tag <p> is safe.
- The parser may optimize a string of HTML removing tags that appear to be the same, forexample:
<b>foo <b>bar</b></b>...becomes...
<b>foo bar</b>Junk in, junk out. The parser is designed to be small and fast. It could perhaps more accurately be thought of as a tag parser rather than an HTML parser, it will do its best to parse whatever you send it but the only sure-fire way to get valid HTML out is to put valid HTML in.
Usage
You can create a String instance using plain text or HTML, for example both of these statements are valid:
// From plain text
var helloWorld = new HTMLString.String('Hello World');
// From HTML
var helloWorldBold = new HTMLString.String('Hello World');For the most part Strings have the same methods as native strings; you can call slice, concat, split, indexOf, and so on - but there are a few things you can't do:
- You can't join them using the + operator.
- Likewise the == operator will compare instances but not content, instead use s.text() or s.html().
- match, replace and search methods do not exist.
There are also a few things you can do with Strings that you can't do with native strings:
- There's support for a number of native string methods that aren't yet supported by all browsers; contains, endsWith, startsWith, trim, trimLeft and trimRight.
- The characters property is an array of all the characters that make up the String. This allows any native array method like splice to be used to modify the characters in place.
- The copy method will return a clean copy of the String (the Tag and Character classes also support this method).
- The format, unformat and hasTags methods provide support for formatting sections of a String with Tags.
- An optimize method is provided to optimize the HTML output by ordering tags, outer to inner, based on the consecutive number of characters they're applied to.
- All methods that accept strings as arguments, such as indexOf, allow either native strings or HTMLString.String instances to be provided. Where comparisons are performed, this difference is important. Native strings are compared without consideration for format, Strings consider the format as well as the content.
Formatting a string
Formatting characters within a string is simple, let's start by creating an unformatted string and applying an italic style to it:
var quote = new HTMLString.String("My pet dragon is called Burt.");
quote = quote.format(0, -1, new HTMLString.Tag('i'));
console.log(quote.html());
>>> '<i>My pet dragon is called Burt.</i>'Now let's imagine I want people to really notice that I have a pet dragon and to prove it I want to link to his Facebook page:
// Remove the old formatting first (not specifying any tags indicates we
// want to clear them all).
quote = quote.unformat(0, -1);
// Make the entire string bold
quote = quote.format(0, -1, new HTMLString.Tag('b'));
// Link to Burt's Facebook profile (we can use reverse indexing to
// select 'burt'.
quote = quote.format(-5, -2, new HTMLString.Tag('a', {'href': '...'}));
console.log(quote.html());
>>> '<b>My pet dragon is called <a href="...">Burt</a>.</b>'Reference
The library consists of 3 classes namespaced under HTMLString:
String
s = new HTMLString.String(html, preserveWhitespace=false)
Create a new String from a native string which can either be plain text or contain HTML. If the preserveWhitespace flag is set to true then white-space within the string will be preserved, if false white-space will be trimmed from either end of the string and collapsed within it.
s.characters
The list of Characters in s.
s.isWhitespace()
Return true if s consists entirely of whitespace Characters. Images (<img ...>), breaks (<br>), and non-breaking spaces ( ) are all considered whitespace.
s.length()
Return the length of s in Characters. To get the length as a native string use s.html().length.
s.capitalize()
Return a copy of s with the first Character capitalized.
s.charAt(index)
Return a single Character from s at the given index. The Character returned is a copy.
s.concat(strings..., inheritFormat=true)
Combine s with one or more strings and return a new String. Optionally you can specify whether the strings each inherit the format of the string they are being concatenated to.
s.contains(substring)
Return true if s contains the substring.
s.endsWith(substring)
Return true if s ends with the substring.
s.format(from, to, tags...)
Return a copy of s with tags applied to Characters in the range from...to.
s.hasTags(tags..., strict=true)
Return true if the tags are applied to some or all characters within s.
s.html()
Return an HTML verion of s.
s.indexOf(substring, from=0)
Return the index of the first occurrence of the substring within s, -1 is returned if no match is found. Optionally you can specify an offset to start searching from.
s.insert(index, string, inheritFormat=true)
Return a copy of s with the specified string inserted at the given index. Optionally you can specify whether the string inherits the format of s.
s.lastIndexOf(substring, from=0)
Return the index of the last occurrence of the specified substring within s, -1 is returned if no match is found. Optionally you can specify an offset to start searching from.
s.optimize()
Optimize the content of s so that tags are stacked in order of run length (see limitations for an example).
s.slice(from, to)
Extract a section of s and return a new String.
s.split(separator='', limit=0)
Split s by the separator and return a list of sub-strings.
s.startsWith(substring)
Return true if s starts with the substring.
s.substr(from, length)
Return a section of s between from and from + length, if length isn't specified the remainder of s will be returned.
s.substring(from, to)
Return a section of s between from and to, if to isn't specified it will default to the length of s.
s.text()
Return a text version of s.
s.toLowerCase()
Return a copy of s converted to lowercase.
s.toUpperCase()
Return a copy of s converted to uppercase.
s.trim()
Return a copy of s with whitespace trimmed from both ends.
s.trimLeft()
Return a copy of s with whitespace trimmed from the left.
s.trimRight()
Return a copy of s with whitespace trimmed from the right.
s.unformat(from, to, tags...)
Remove the tags from a range (from, to) of Characters in s. Specifying no tags will clear all formatting from the selection. The list of tags provided can either be Tag instances or tag names. Using Tags will mean that the match is performed on both a Tag's attributes and name.
s.copy()
Return a copy of s.
HTMLString.String.encode(string)
Return a copy of a native string with all required characters encoded as HTML entities.
HTMLString.String.decode(string)
Return a copy of a native string with all HTML entities decoded.
HTMLString.String.join(separator, strings)
Join a list of strings together using the separator string and return the result.
Tag
tag = new HTMLString.Tag(name, attributes={})
Create a new Tag using the given tag name and attributes. The attributes are specified as key/value pairs in an object.
tag.head()
Return the tag's head (e.g <p>).
tag.name()
Return the name for the tag.
tag.selfClosing()
Return true if the tag is self-closing.
tag.tail()
Return the tag's tail (e.g </p>).
tag.attr(name, [value])
Get/Set the value of the named attribute for the tag. If a value is provided then the attribute will be set, else its value will be returned.
tag.removeAttr(name)
Remove the named attribute from the tag.
tag.copy()
Return a copy of the tag.
Character
character = new HTMLString.Character(c, tags=[])
Create a new Character, optionally with the given list of tags.
character.c()
Return the native string for the character.
character.isEntity()
Return true if the character is an entity.
character.isTag(tagName)
Return true if the character represents a self-closing tag (e.g <br>, <img...>, etc), optionally a tagName can be specified to match against.
character.isWhitespace()
Return true if the character represents a whitespace character including images (<img ...>), breaks (<br>), and non-breaking spaces ( ).
character.tags()
Return the tags applied to the character.
character.addTags(tags...)
Add one or more tags to the character.
character.eq(otherCharacter)
Return true if otherCharacter is equal to this character. All applied tags for both characters must also match.
character.hasTags(tags...)
Return true if all the given tags are used to format the character.
character.removeTags(tags...)
Remove one or more tags from the character.
character.copy()
Return a copy of the character.